Server class¶
This class is the core of the federated learning simulation in fluke. When you start to extend it,
make sure to have a clear understanding of what are the data exchanged between the server and the clients and
how the learning process is orchestrated. This is crucial to avoid introducing bugs and to keep the code clean.
Overview¶
The Server class is the one responsible for coordinating the federated learning process.
The learning process starts when the fit method is called on the Server. Inside the fit method, the server will iterate over the number of rounds specified in the argument n_rounds.
Each significant server’s operation trigger a notification of the observers that have been registered to the server.
Finally, at the end of the fit, the server will finalize the federated learning process.
Server initialization¶
The Server constructor is responsible for initializing the server. Usually, there is not much more to it than initializing the server’s attributes.
However, there is an important notion that you should be aware of: all the server’s hyperparameters should be set in the hyper_params attribute that is a DDict. This best practice ensure that the hyperparameters are easily accessible and stored in a single place.
Sequence of operations of a single round¶
The standard behaviour of the Server class (as provided in the class Server) follows the sequence of operations of the Federate Averaging algorithm. The main methods of the Server class involved in a single federated round are:
get_eligible_clients: this method is called at the beginning of each round to select the clients that will participate in the round. The selection is based on the
eligible_percargument of the fit method.broadcast_model: this method is called at the beginning of each round to send the global model to the clients that will participate in that round.
aggregate: this method is called towards the end of each round to aggregate the models of the clients that participated in the round.
evaluate: this method is called at the end of each round to evaluate the global model on a held out test set (if any). The evaluation can also be performed client-side.
finalize: this method is called at the end of the fit method to finalize the federated learning process - if needed.
The following figure shows the sequence of operations of the Server class during the fit method.
Disclaimer
For brevity, many details have been omitted or simplified. However, the figure below shows the key methods and calls involved in a round.
For a complete description of the fluke.server.Server class, please refer to the Server’s API documentation.
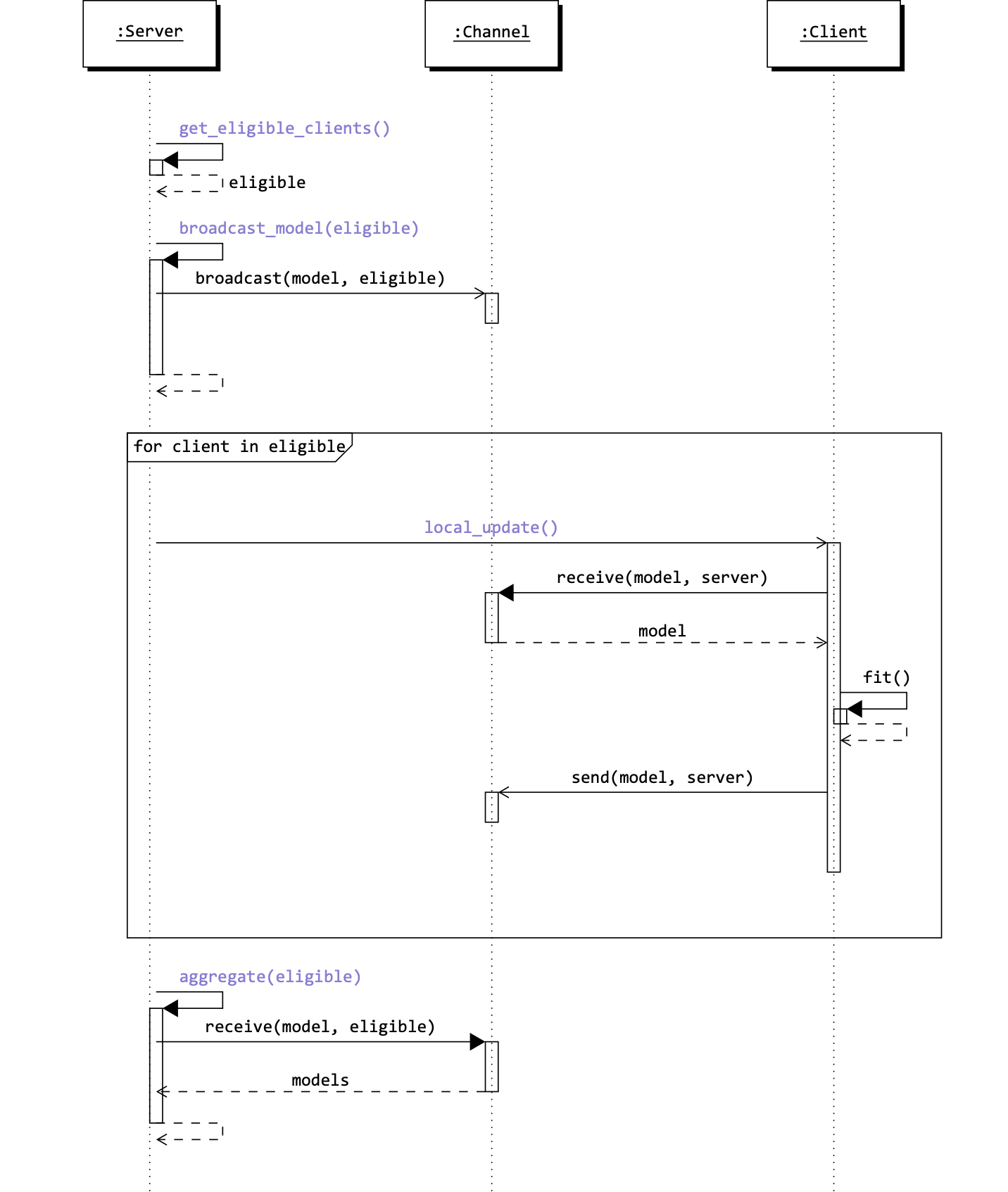
Sequence of operations of the Server class during the fit method. This image has been created with TikZ [source].¶
The sequence diagram above shows the sequence of operations of the Server class during a single round. It highlights the dependencies between the methods of the Server class and the Client class. Moreover, it shows that the communication between the server and the clients is done through the Channel. The only direct call between the server and the client is the local_update method of the Client class that is called to trigger the beginning of the training process on the client side.
Finalization¶
At the end of the fit method, the Server class will finalize the federated learning process by calling the finalize method. Ideally, this method should be used to perform any final operation, for example, to get the final evaluation of the global (and/or local) model(s), or to save the model(s). It can also be used to trigger fine-tuning operations client-side as it happens in personalized federated learning.
Observer pattern¶
As mentioned above, the Server class triggers notifications to the observers that have been registered to the server. The default notifications are:
selected_clients: triggered after the clients have been selected for the round.
server_evaluation: it should be triggered after an evaluation has been performed.
track_item: it should be triggered to track any item of interest.
Hint
Refer to the API documentation of the ServerObserver inerface and the ObserverSubject intarface for more details.
Creating your Server class¶
Creating a custom Server class is straightforward. You need to create a class that inherits from the Server class and override the methods that you want to customize. As long as the federated protocol you are implementing follows the standard Federated Averaging protocol, you can reuse the default implementation of the fit method and override only the methods that are specific to your federated protocol.
Let’s see an example of a custom Server class that overrides the aggregate method while keeping the default implementation of the other methods.
Hint
Here we show a single example but you can check all the following algorithm implementations to see
other examples of custom fluke.server.Server.aggregate():
The example follows the implementation of the FedExP algorithm. We also report the standard implementation of the aggregate method for comparison.
1@torch.no_grad()
2def aggregate(self, eligible: Sequence[Client], client_models: Collection[Module]) -> None:
3 W = flatten_parameters(self.model)
4 client_models = list(client_models)
5 Wi = [flatten_parameters(client_model) for client_model in client_models]
6 eta = self._compute_eta(W, Wi)
7 self.hyper_params.update(lr=eta)
8 super().aggregate(eligible, client_models)
9
10def _compute_eta(self, W: torch.Tensor, Wi: list[torch.Tensor], eps: float = 1e-4) -> float:
11 ...
1@torch.no_grad()
2def aggregate(self, eligible: Sequence[Client], client_models: Collection[Module]) -> None:
3 weights = self._get_client_weights(eligible)
4 aggregate_models(self.model, client_models, weights, self.hyper_params.lr, inplace=True)
Let’s start by summarizing the implementation of the FedAVG’s aggregate method. The goal of this method is to aggregate the models of the clients that participated in the round to update the global model.
The aggregation is done by computing the weighted average of the models of the clients (client_models). Thus, the method first collects the weights of the clients (self._get_client_weights(eligible)).
Finally, the global model is updated by calling the aggregate_models function that computes the weighted average of the models of the clients.
The custom implementation of the aggregate method for the FedExP algorithm follows a slightly different approach.
The main difference lies in the update rule of the global model that uses a different learning rate for each round.
Indeed, lines 3-7 show how the learning rate is computed and then the corresponding learning rate is set in the hyperparameters of the server.
Finally, the global model is updated using the standard implementation of the aggregate method.
Please, refer to the original paper of the FedExP algorithm for more details on the update rule.
Tip
In general, when you extend the fluke.server.Server class, you should start overriding the methods from the implementation provided in the fluke.server.Server class and
then modify only those aspects that do not suit your federated protocol trying to preserve as much as possible the default implementation.
Similar considerations can be made for the other cases when the there is no need to override the fit.
Attention
When overriding methods that require to notify the observers, make sure to call the corresponding
notification method of the fluke.ObserverSubject interface. For example, if you override the fluke.server.Server.finalize() method you should call the notify method for
the event “finalize” at the end of the method. For example, see the implementation of FedBABU.
The fit method¶
Sometimes you might also need to override the fit method of the Server class. This is the case when the federated protocol you are implementing requires a different sequence of operations than the standard Federated Averaging protocol.
This is quite uncommon but it can happen. Currently, in fluke, the only algorithms that overrides the fit method are FedHP and FedDyn. In both these cases, the protocol differs from the standard Federated Averaging protocol only in the starting phase of the learning and hence the fit method is overridden to
add such additional operations and then the super().fit() is called to trigger the standard behaviour.
When overriding the fit method, you should follow the following best practices:
Progress bars: track the progress of the learning process using progress bars. In
fluke, this this is done using the rich library. Inrich, progress bars and status indicators use a live display that is an instance of theLiveclass. You can reuse theLiveinstance offlukefrom the FlukeENV using the get_live_renderer method. In this live display, you can show the progress of the client-side and server-side learning already available in the FlukeENV usingget_progress_bar("clients")andget_progress_bar("server"). Then to update the progress bars and to get more information on how to use therichlibrary, please refer to the official documentation.The following is an excert of the fit method, showing how to initialize the progress bars:
1with FlukeENV().get_live_renderer(): 2 progress_fl = FlukeENV().get_progress_bar("FL") 3 progress_client = FlukeENV().get_progress_bar("clients") 4 client_x_round = int(self.n_clients * eligible_perc) 5 task_rounds = progress_fl.add_task("[red]FL Rounds", total=n_rounds*client_x_round) 6 task_local = progress_client.add_task("[green]Local Training", total=client_x_round) 7 ...
Communication: in
fluke, generally, clients and server should not call each other methods directly. There are very few exceptions to this rule, for example, when the server needs to trigger the local update on the client side or when the server asks to perform the evaluation. In all other cases, the communication between the server and the clients should be done through the Channel. The Channel instance is available in the Server class (channel property) and it must be used to send/receive messages. Messages must be encapsulated in a Message object. Using the channel enablesfluke, through the logger (see Log), to keep track of the exchanged messages and so it will automatically compute the communication cost. The following is the implementation of the broadcast_model method that uses the Channel to send the global model to the clients:1def broadcast_model(self, eligible: Sequence[Client]) -> None: 2 self.channel.broadcast(Message(self.model, "model", self), [c.index for c in eligible])
Minimal changes principle: this principle universally applies to software development but it is particularly important when overriding the fit method because it represents the point where the whole simulation is orchestrated. Start by copying the standard implementation of the fit method and then modify only the parts that are specific to your federated protocol. This will help you to keep the code clean and to avoid introducing nasty bugs.