Client class¶
We suggest to start from the Client class when you want to implement a new federated learning algorithm.
Often, the Client class is the most complex class to implement and maybe the “only one” (you have to implement the class for the algorithm too but it is usually a metter of overriding a couple of get methods) that you need to implement.
Overview¶
In fluke, the Client class represents the client-side logic of a federated learning algorithm. This is generally the part where most of the magic happens.
Client initialization¶
The Client constructor is responsible for initializing the client. Usually, there is not much more to it than setting the client’s attributes. However, there are some important notions that you should be aware of:
all the client’s hyperparameters should be set in the
hyper_paramsattribute that is a DDict. This best practice ensure that the hyperparameters are easily accessible and stored in a single place;the optimizer and the scheduler are not initialized in the constructor becuase the client does not own a model yet. They are initialized in the
fitmethod. This should be done using theoptimizer_cfg(see OptimizerConfigurator) attribute that is a callable that returns the optimizer and the scheduler. This is done to allow the optimizer to be initialized with the correct model parameters.
The following excperts show the constructor of the Client class an hypothetical new client class.
1def __init__(self,
2 index: int,
3 train_set: FastDataLoader,
4 test_set: FastDataLoader,
5 optimizer_cfg: OptimizerConfigurator,
6 loss_fn: torch.nn.Module,
7 local_epochs: int):
8 self.hyper_params: DDict = DDict(
9 loss_fn=loss_fn,
10 local_epochs=local_epochs
11 )
12
13 self._index: int = index
14 self.train_set: FastDataLoader = train_set
15 self.test_set: FastDataLoader = test_set
16 self.model: Module = None
17 self.optimizer_cfg: OptimizerConfigurator = optimizer_cfg
18 self.optimizer: Optimizer = None
19 self.scheduler: LRScheduler = None
20 self.device: device = FlukeENV().get_device()
21 self._channel: Channel = None
22 self._last_round: int = 0
1def __init__(self,
2 index: int,
3 train_set: FastDataLoader,
4 test_set: FastDataLoader,
5 optimizer_cfg: OptimizerConfigurator,
6 loss_fn: torch.nn.Module,
7 local_epochs: int,
8 my_hp1: float,
9 my_hp2: float):
10 super().__init__(index, train_set, test_set, optimizer_cfg, loss_fn, local_epochs)
11 self.hyper_params.update(hp1=my_hp1, hp2=my_hp2)
Client-side training¶
The main method that characterizes the client’s behaviour is the fit method which is responsible for training the local model;
This method is wrapped inside the method local_update which is also responsible of the communication with the server and to perform the evaluation.
The following figure shows the sequence of operations of the Client class during the local_update method.
Disclaimer
For brevity, many details have been omitted or simplified. However, the figure below shows the key methods and calls involved.
For a complete description of the Client class, please refer to the Client’s API documentation.
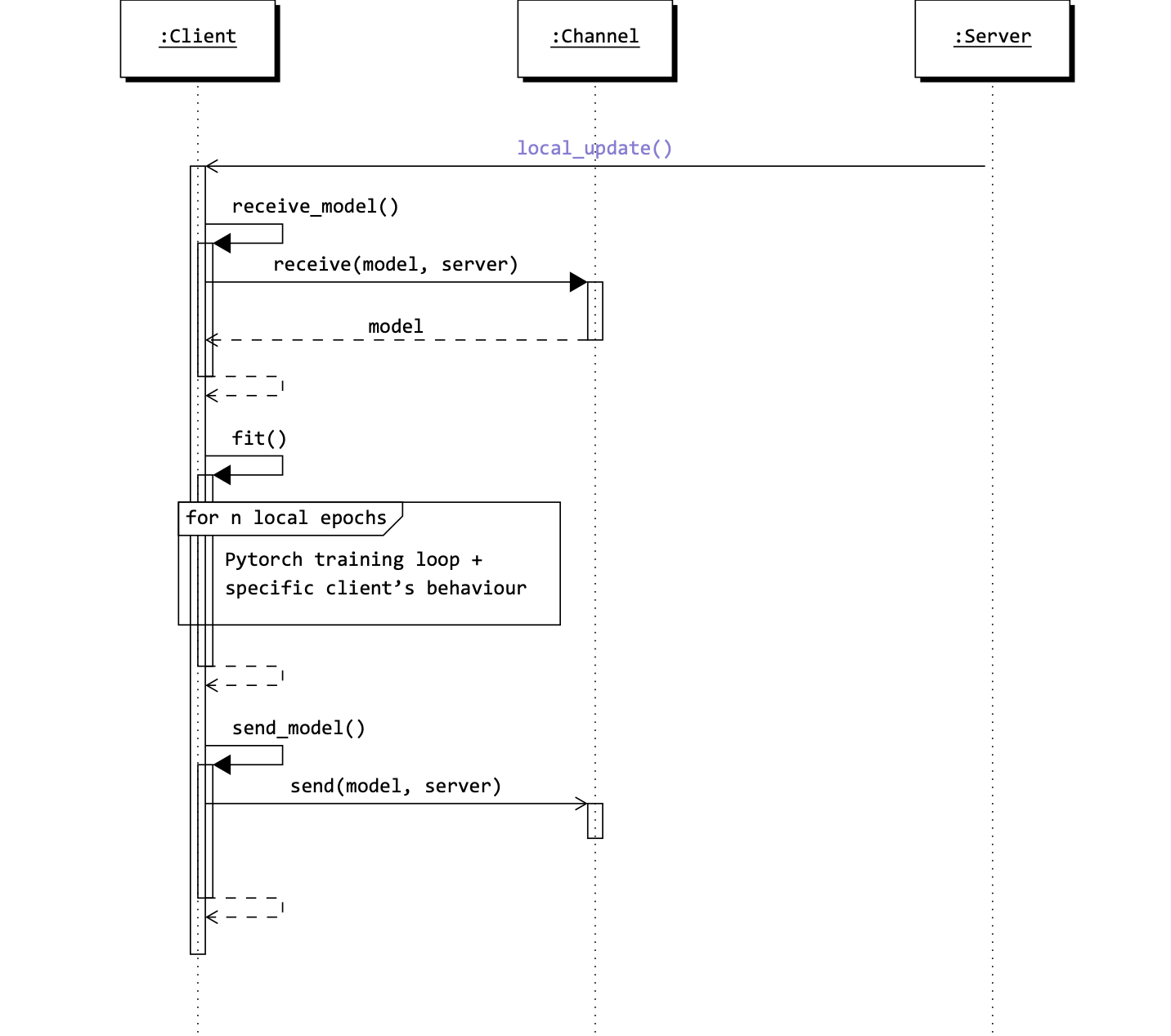
Sequence of operations of the Client class during the fit method.
This image has been created with TikZ [source].¶
The local_update method is called by the server when it is time to train the local model on the client’s data.
Attention
In general, the communication between the server and the client should be done through a Channel. Direct methods calls must be only used to trigger events and not to exchange data.
The client receives the global model from the server, trains the local model on its data, and sends the updated model back to the server:
receive_model: this method simply retrieves the global model sent by the server. It is indeed important to make sure that the server has sent the model before calling this method. Although it is namedreceive_model, the message may also contain additional information that the client may need to process/use (for example, see SCAFFOLD).send_model: this method sends the updated model back to the server.
Usualy, most of the logic of a federated learning algorithm is implemented in the fit method, where the training loop happens!
The training loop¶
There is not much to say about the training loop itself. fluke is design to work with PyTorch models even though it can be easily extended to work with other frameworks. The training loop is the same as any other training loop in PyTorch. We suggest that you take a look at the PyTorch documentation for more information on how to train a model in PyTorch.
Tip
Make sure to move the model to the correct device before training it. Be careful to move it back to the CPU before sending it to the server. Cleaning up the CUDA cache is also a good practice to avoid memory leaks fluke.utils.clear_cuda_cache. This loading-unloading process on GPU may lead to a performance penalty in some cases (e.g., with many small models that could fit in the GPU memory at the same time). We plan to introduce a more efficient way to handle this in the future.
The following code snippet shows the fit method of the Client class.
1def fit(self, override_local_epochs: int = 0) -> float:
2 epochs: int = (override_local_epochs if override_local_epochs
3 else self.hyper_params.local_epochs)
4 self.model.train()
5 self.model.to(self.device)
6
7 if self.optimizer is None:
8 self.optimizer, self.scheduler = self.optimizer_cfg(self.model)
9
10 running_loss: float = 0.0
11 for _ in range(epochs):
12 for _, (X, y) in enumerate(self.train_set):
13 X, y = X.to(self.device), y.to(self.device)
14 self.optimizer.zero_grad()
15 y_hat = self.model(X)
16 loss = self.hyper_params.loss_fn(y_hat, y)
17 loss.backward()
18 self.optimizer.step()
19 running_loss += loss.item()
20 self.scheduler.step()
21
22 running_loss /= (epochs * len(self.train_set))
23 self.model.to("cpu")
24 clear_cuda_cache()
25 return running_loss
Finalization¶
After all the rounds are completed, the server may call the finalize method on the client (see server customization). This method is responsible for any finalization steps that the client may need to perform. For example, performing fine-tuning on the local model, saving the model, or sending any final information to the server. In its default implementation, the finalize method simply receives the final global model from the server. This will allow the client to have the most up-to-date global model to be used for an eventual evaluation.
Personalized Federated Learning Client¶
If you are implementing a new personalized federated learning algorithm, you should inherit from the PFLClient class instead of the Client class. The personalized version of the client class has an additional attribute (personalized_model) representing the personalized model.
Differently from the usual local model, the personalized one is initialized by the client itself and hence the constructor requires an additional argument model that is the personalized model. The last difference lies in the evaluation method (evaluate) that uses the personalized model instead of the local model.
As always, you can override all the methods you need to customize the behavior of the client.
Creating your Client class¶
To create your own Client class, you need to inherit from the Client (or PFLCLient) class. The suggested steps to create a new Client class are:
Define the constructor of the class and set the hyperparameters in the
hyper_paramsattribute. All the inherited attributes should be set calling the super constructor. Here, you can also set any additional attributes that you may need.Override the
fitmethod. This method is responsible for training the local model on the client’s data and sending the updated model to the server. This is where most of the logic of your algorithm should be implemented. If you need some support methods, define them privately (i.e., use the prefix ‘_’ to indicate that the method is private).If necessary, override the
finalizemethod.
Likewise the Server class, you should follow the following best practices:
Communication: in
fluke, generally, clients and server should not call each other methods directly. There are very few exceptions to this rule, for example, when the server needs to trigger an event client-side and viceversa. In all other cases, the communication between the server and the clients should be done through theChannelclass (see the Channel API reference). TheChannelinstance is available in theClientclass (_channelprivate instance orchannelproperty) and it must be used to send/receive messages. Messages must be encapsulated in a Message object. Using a channel allowsfluke, through the logger (see Log), to keep track of the exchanged messages and so it will automatically compute the communication cost. The following is the implementation of thesend_modelmethod that uses theChannelto send the global model to the clients:1def send_model(self) -> None: 2 self.channel.send(Message(self.model, "model", self.index), "server")
Minimal changes principle: this principle universally applies to software development but it is particularly important when overriding the
fitmethod. Start by copying the standard implementation of thefitmethod and then modify only the parts that are specific to your federated protocol. This will help you to keep the code clean and to avoid introducing nasty bugs.
The following is an example of the FedProxClient class (see FedProx) where we highlighted in the fit method the only lines of code that differ from the FedAVG implementation.
1class FedProxClient(Client):
2 def __init__(self,
3 index: int,
4 train_set: FastDataLoader,
5 test_set: FastDataLoader,
6 optimizer_cfg: OptimizerConfigurator,
7 loss_fn: torch.nn.Module,
8 local_epochs: int,
9 mu: float):
10 super().__init__(index, train_set, test_set, optimizer_cfg, loss_fn, local_epochs)
11 self.hyper_params.update(mu=mu) # Add the mu hyperparameter
12
13 # Support method to compute the proximal term
14 def _proximal_loss(self, local_model, global_model):
15 proximal_term = 0.0
16 for w, w_t in zip(local_model.parameters(), global_model.parameters()):
17 proximal_term += torch.norm(w - w_t)**2
18 return proximal_term
19
20 def fit(self, override_local_epochs: int = 0) -> float
21 epochs = override_local_epochs if override_local_epochs else self.hyper_params.local_epochs
22 W = deepcopy(self.model)
23 self.model.to(self.device)
24 self.model.train()
25 if self.optimizer is None:
26 self.optimizer, self.scheduler = self.optimizer_cfg(self.model)
27 for _ in range(epochs):
28 loss = None
29 for _, (X, y) in enumerate(self.train_set):
30 X, y = X.to(self.device), y.to(self.device)
31 self.optimizer.zero_grad()
32 y_hat = self.model(X)
33 loss = self.hyper_params.loss_fn(y_hat, y) + \
34 (self.hyper_params.mu / 2) * self._proximal_loss(self.model, W)
35 loss.backward()
36 self.optimizer.step()
37 self.scheduler.step()
38
39 self.model.to("cpu")
40 clear_cuda_cache()
Observer pattern¶
The Client class triggers callbacks to the observers that have been registered to the client.
The default notifications are:
notify(event="start_fit", ...): triggered at the beginning of thefitmethod. It callsClientObserver.start_fiton each observer;notify(event="end_fit", ...): triggered at the end of thefitmethod. It callsClientObserver.end_fiton each observer;notify(event="client_evaluation", ...): it should be triggered after an evaluation has been performed. It callsClientObserver.evaluationon each observer;
Hint
Refer to the API documentation of the ClientObserver inerface and the ObserverSubject intarface for more details.